(open-source, UTF-16, OSM – hipsteraj na sve strane)
Elem, išao ja tako kod druga koji živi u Đakovačkoj i ispadne da OsmAnd Android navigacija ne može da pronađe ovu ulicu, iako ulica postoji! Iznerviram se tu i rešim da sredim stvari. Ja sam Kokan, a ovo su open-source hirurgije:)
Disclaimer: Ovaj tekst, kao uostalom i svi moji tekstovi ovde, je pun random informacija, blebetanja, gomile nepoznatih tehnologija/framework-a/aplikacija, a sve referencirano linkovima, tako da čovek lako odustane. Ako ne odustaneš, dragi čitaoče, saznaćeš dok čitaš pregršt novih stvari, a ako ti bar jedna od njih bude zanimljiva da istražuješ dalje, uspeo sam!:)
OSM – kralj mapa:)
OpenStreetMap (OSM u daljem tekstu) je jedan jako interesantan i dobar pokret, najbolje objašnjen kao “Wikipedija za mape”. Zahvaljujući gomili naših ljudi koji ovde mapiraju stvari, Srbija je urađena prilično kvalitetno, a veći gradovi isto (ako ne i bolje) od drugih sličnih alata, kao Here Maps, Google Maps…Uostalom, krenite odavde, uzumirajte vaše mesto, pa se uverite i sami. Nije komercijalni proizvod, ali mislim da je veoma upotrebljiv – dajte mu šansu. OSM je zapravo skup servisa, a tu ima gomila stvari od kojih OSM zavisi i koje zavise od njega; unošenje podataka je samo jedna od stvari, a tu su i:
- skladištenje podataka (baza je Postgres, ali tu su GIS dodaci za baze i neke druge serijalizacije, od kojih je najpopularniji PBF format koji koristi Google protobuffer),
- prikaz tih podataka:
- ima gomila renderer-a tu ali se Mapnik izdvaja kao de facto standard, kao i
- web biblioteka koje to mogu prikazati, najpoznatije su Leaflet i OpenLayers u JS-u (mada daleko od toga da je vizuelizacija ograničena samo na web)
- navigacija (navigacija je, po meni, trenutno najslabija tačka OSM-a jer i najmanja greška (pogrešna brzina tagovana, loše spojena ulica, ulica nije označena kao jednosmerna) može da napravi razliku između upotrebljive i neupotrebljive navigacije. Kao što se vidi na linku, softvera ima mnogo, mogućnosti su neverovatne, ali kvalitet mapa mora da je veći da bi se ovo koristilo. U Beogradu i Novom Sadu je npr. upotrebljivo, ali iskreno, ne bih smeo da koristim OSM za navigaciju u manjim mestima… još par godina)
- street-level slike (BTW, ovaj startup radi i machine learning za prepoznavanje znakova, ulica i sl., a kao što može da se vidi, a i Srbija je skroz pokrivena slikama, što je mene baš iznenadilo… zajednica je baš jaka)
- integracija sa mobilnim aplikacijama…
Ekosistem je ogroman, a ja…ja koristim već pomenuti OsmAnd+ u svakodnevnom radu (za navigaciju, pretrage, hiking…).
Elem, da se vratim na osnovni problem – gre’ota je bre da imamo ovoliko podataka unesenih, a kad mali Pera dođe i otkuca “Zorana Djindjica“, da ne može da je nađe; to pod jedan tera ljude od ovih sjajnih mapa, a takođe i poništava rad svih onih kartografa koji rade na srpskim mapama, i to zbog čega – zbog (ispostaviće se) glupe greške u softveru.
Upoznajte Nominatim – OSM search engine
Da bismo provalili zašto OsmAnd+ ne nalazi Đakovačku, prvo moramo saznati kako OsmAnd+ radi pretragu. Ispostavlja se da OsmAnd+ koristi Nominatim da bi našao sve podatke. Šta je sad Nominatim, pitate se. Nominatim je search engine za OSM. I stvarno, ako otkucate “Đakovačka“, naći ćete tu ulicu. Ako pak otkucate “Ђаковачка“, isto ćete je naći. Ali ako otkucate “Djakovacka” (romanizovana ili ošišana latinica), nema je! (ili je bar nije bilo pre nego što sam se ja umešao:)
Normalizacija
Sledeći korak je zaviriti u dubine Nominatim engine-a i videti kako on radi magiju pretrage. Posle malo istraživanja i kopanja po source kôdu, zaključi se da Nominatim roka sve podatke u PostgreSQL bazu alatom osm2pgsql i da u samoj bazi, tako što postoji Postgres modul pisan u C-u, sve podatke interno “normalizuju” u tzv. mašinsku latinicu, tj. postoji mapa iz Unicode UTF-16 znakova u ekvivalentan skup latiničnih znakova (jednog ili više). Kôd za uvoženje je ovde, a sama mapa iz UTF-16 u mašinku latinicu je ovde (nečitljivo je za čoveka:). Tako npr. “Ǎ” postaje obično “A”, grčko “Ξ” postaje “KS”, a naše “Ш” postaje “SH”. I eto tako svi kuke i kvake ovog sveta završe kao latinica u bazi ispod. Kada se radi pretraga, onda se sa zadatim upitom radi ista ovakva transformancija i onda se upoređuju dve mašinske latinice. Ovo je manje-više ono što i treba da se radi u ovakvim situacijama, ali i dalje nije jasno “pa zašto Djakovacka onda ne radi!” Da bismo to saznali, najbolje je da vidimo šta su mašinski ekvivalenti naših slova, i ćirilice i latinice. Da bih video to, najlakše je bilo da uzmem postojeći kôd od Postgres modula koji radi normalizaciju i prepravim ga da radi ona slova koja ja hoću da uradi:) Ceo kôd se sveo na ovo (ne ložim vas, ovo je stvarno ceo kôd:):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | // lokalno snimljena pmapa UTF-16 => masinska latinica #include "Nominatim\module\utfasciitable.h" #include #include void main() { static char * ascii = UTFASCII; static uint16_t asciilookup[65536] = UTFASCIILOOKUP; char * asciipos; unsigned char *sourcedata; int sourcedatalength; uint16_t * wchardata; uint16_t * wchardatastart = (uint16_t*)\ L"A B V G D Đ E Ž Z I - J K L LJ M N NJ O P R - S T Ć U F H C Č DŽ Š" "А Б В Г Д Ђ Е Ж З И - Ј К Л Љ М Н Њ О П Р - С Т Ћ У Ф Х Ц Ч Џ Ш"; unsigned char *resultdata= new unsigned char[10000]; unsigned char* resultdatastart = resultdata; int iLen; wchardata = wchardatastart; while (*wchardata) { if (*(asciilookup + *wchardata) > 0) { asciipos = ascii + *(asciilookup + *wchardata); for (iLen = *asciipos; iLen > 0; iLen--) { asciipos++; *resultdata = *asciipos; resultdata++; } } wchardata++; } *resultdata = '\0'; printf("%s", resultdatastart); } |
I još jednom, da se razumemo – više sam kôda izbrisao nego dodao!:)
Pobrkani lončići
Predstavljeno tabelarno, ta sva preslikavanja izgledaju nekako ovako:
| Skript | Slova | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ćirilica | А | Б | В | Г | Д | Ђ | Е | Ж | З | И | Ј | К | Л | Љ | М | Н | Њ | О | П | Р | С | Т | Ћ | У | Ф | Х | Ц | Ч | Џ | Ш |
| Latinica | А | B | V | G | D | Đ | E | Ž | Z | I | J | K | L | LJ | M | N | NJ | O | P | R | S | T | Ć | U | F | H | C | Č | DŽ | Š |
| Ošišana latinica | А | B | V | G | D | DJ | E | Z | Z | I | J | K | L | LJ | M | N | NJ | O | P | R | S | T | C | U | F | H | C | C | DZ | S |
| Mašinska ćirilica | А | B | V | G | D | DJ | IE | ZH | Z | I | J | K | L | LJ | M | N | NJ | O | P | R | S | T | TSH | U | F | KH | TS | CH | DZH | SH |
| Mašinska latinica | А | B | V | G | D | D | E | Z | Z | I | J | K | L | LJ | M | N | NJ | O | P | R | S | T | C | U | F | H | C | C | DZ | S |
Na prvi pogled, deluje da je mašinska latinica jako bliska našoj ošišanoj latinici, osim na jednom mestu – slovu “Đ” koje postaje “D” (a trebalo bi da bude “DJ”). Ćirilica je užasno pogrešna na gomili mesta. Na ovom mestu bih napravio malu digresiju i rekao da srpski OSM ima unesene i ćirilične i latinične nazive svih entiteta (mesta, okruga, ulica…), prve u “name:sr” tagu, a druge u “name:sr-Latn” tagu. I ćirilični i latinični nazivi se uvoze u Postgres bazu. Neki čitaoci su možda do sad već naslutili u kom grmu leži zec, ali idemo polako. “Ђаковачка” će se normalizovati u “DJAKOVACHKA”. Latinična “Đakovačka” će se normalizovati u “DAKOVACKA”. Ljudi koji traže pojmove ošišanom latinicom imaju samo sreće što se mašinska latinica manje-više poklapa sa našom ošišanom latinicom. Tj. imaju sreće ukoliko ne traže pojam koji ima slovo “Đ”:) Inače, funny fact – primetite da pretraga pojmova i “DJAKOVACHKA” i “DAKOVACKA” radi sasvim lepo:) (sad znate i zašto:)
OK, jasno je da imamo problem sa slovom “Đ”, ali kako onda da pretraga za “Djurina” radi??? Zar se “Đurina” ne normalizuje u “Durina”? Jeste, da, ali pošto Nominativ uvozi i “name:sr” koji ima vrednost “Ђурина”, onda će to biti normalizovano kao “Djurina” i uspećemo da je nađemo (slučajnim spletom okolnosti da je ćirilično “Ђ” lepo normalizovano u “DJ”). Nažalost, to važi u samo ograničenom broju slučajeva, jer će npr. “Синђелићева” biti normalizovana u “Sindjielitshieva” i ode sve u k. (matematički precizno, radi samo u onim slučajevima u kojima u ćirličnom nazivu nema slova kojima se mašinska latinica razlikuje od naše ošišane latinice, a to su slova “e”, “ž”, “ć”, “h”, “c”, “č”, “dž” i “š”).
Open source priskače u pomoć
Prva stvar koja padne na pamet je da se sve ovo ispravi direktno u Nominatimu. Idealno bi bilo promeniti da se “Đ” pretvara u “DJ” (da jurimo bolje pretvaranje ćiriličnih karaketera je suludo). Međutim, ovo nije baš backward kompatibilna izmena, pošto se “Đ” koristi u dosta jezika (od balkanskih, preko finskih i vijetnamskih…) I ja sam bio iznenađen kad sam to saznao, dosta sam kopao dok nisam našao ovu tabelu mapiranja u kom se jeziku koriste koji UTF karakteri – bookmarkujte, ko zna kad će da zatreba:) Nazad na bug, rekoh lako bi bilo načiniti izmenu, ali mislim da bi to bilo neprihvatljivo Vijetnamcima, braći Hrvatima i celoj deželi:) Napravio sam issue na GitHub-u za Nominatim, ali slabe su mi nade da će se ovo izmeniti ikada. Nisam siguran za Vijetnamce i Fince, ali je ironija što bi i braći Hrvatima i Slovencima značilo da se “Đ” mapira u “DJ”, pošto i oni tako romanizuju “Đ”. Tu nisam mogao mnogo da pomognem osim da ih obavestim da sam našao bug i da treba da znaju da on postoji.
Ako neće Muhamed bregu…
OK, ako Nominatim ne može ovo da izmeni, moramo mi da izmenimo kod nas. Želimo da, kada čovek otkuca “Djakovacka”, da dobije rezultat pretrage. Nije sigurno opcija da prebacujemo ni “name:sr” ni “name:sr-Latn” u ošišanu latinicu, tako da nam je trebao neki drugi tag koji se uvozi u Nominatim (na svu sreću, Nominatim uvozi punu k. tagova (k. je od “kapu”) . Posle kraće brainstorming sesije na forumu, Peđa je predložio da iskoristimo “int_name“, a meni se to baš svidelo. Po definiciji, to je najsličnije onome što nam treba. Druga stvar je – pored toga što smo smislili gde ćemo da pišemo novo ime, trebalo je smisliti da li upisivati ovo bespogovorno za sve entitete sa mape ili samo tamo gde je potrebno. Po meni, treba ga upisati samo tamo gde je potrebno (da ne zagađujemo bazu izračunljivim stvarima ako nema potrebe), a to su slučajevi kada u latiničnom imenu imamo bar jedno slovo “đ” (teorijski, mogli bi da izbegnemo mesta koja nemaju nijedno od slova “e”, “ž”, “ć”, “h”, “c”, “č”, “dž” i “š” pošto bi ih onda pokrila ćirilična verzija imena, ali mislim da je to dosta velika komplikacija i cinculiranje, pošto dosta imena ima bar jedan od ovih karaktera).
Da bismo vizuelizovali sva mesta koja imaju “đ”, iskoristio sam Sophox servis. Sophox je jedan mnogo moćan alat kome se može zadati SPARQL upit i on može da prikaže rezultat. I ne samo to! Pored prikaza rezultata, u logiku upita može da se zada i koja se promena želi napraviti u OSM-u i on može da ponudi korisniku da direktno menja OSM (ako je ulogovan). Konačni upit koji je u stanju da nađe sva ova imena i da predloži željene promene može da se nađe na ovom linku. Kliknite dugme “Play” i dobićete ubrzo kartu sa svim entitetima sa slovom “đ” i moći ćete i vi da pomognete tako što je ćete moći da “ispravljate” stvari (da biste actually menjali išta, morate imati nalog za OSM, da budete ulogovani, a i da zumirate, pošto nije dozvoljeno menjanje ako ste na većim “visinama”). Ne čudite se ako dobijete 0 redova, to znači da su svi “int_name” tagovi dodati pravilno:) U trenutku pre nego što sam počeo dodavanje “int_name” taga, situacija je bila takva da je on falio na oko 2100 mesta.
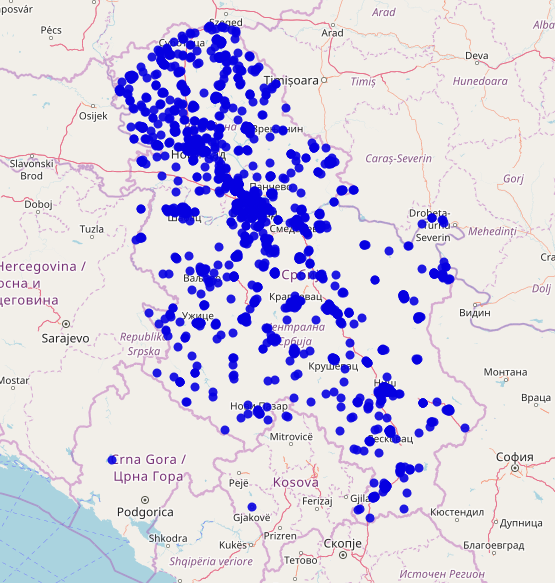
Ne znam kakva je mapa kada ti čitaoče danas klikneš na ovaj link iznad, ali se nadam da nema mnogo zaostalih mesta:) Da ovekovečimo početno st(r)anje stvari, evo kako su krajem 2017.-e izgledala sva mesta sa slovom “đ” na mapi cele Srbije (kojima fali “int_name” tag):

A evo i kako izgledaju kad malo zumirano:

I na kraju, evo prikaz Novog Sada, sa jednom ulicom kojoj treba malo…”ubeđivanja”:

E, sad, da bismo brzo pročistili sva ova mesta, i da bismo održavali stanje stvari koliko-toliko urednim, ne bi bilo normalno da to radimo ručno. Iz rukava sam izvukao mog poluautomatizovanog bota koji već radi razne provere na teritoriji Srbije (a tako sam i uočio ovaj problem), neiventivno nazvanog Serbian OSM Lint. Doduše, botu je trebala integracija sa Sophox alatom, pa sam dodao da bot, pored toga što može da čita PBF, može da za ulazne podatke dobije i preko Sophox SPARQL upita (plan mi je da jednog dana batalim PBF pošto je mnooogo sporiji od Sophox-a, ali to je neka druga tema). Bot mi je tu nemerljivo pomogao da lako dodamo “int_name”, a sada je deo redovnih provera koje se (skoro pa) redovno ažuriraju na njegovoj strani (pogledajte, ima tu raznih provera preko ovog bota).
Zaključak
Ili kako to današnji klinci kažu TL;DR
Prosto ne verujem da si pročitao sve dovde, dragi čitaoče (vrlo verovatnije je da si prelistavao polako sve i onda došao ovde, zar ne;) – nije to ništa strašno, živi se brzo, al’ hranimo se zato lako:) Ali eto, jedan potpun, lep blog post – ima slike, ima tabelu, ima source kôd; ima ženske, ima sve. U svakom slučaju, poenta koju sam hteo da kažem, koju trebate pokupiti odavde i key take-aways, što bi rekli Ameri, se mogu svesti na:
- Postoji nešto što se zove OpenStreetMap, otvorene mape koje svako može da uređuje i mnogo su dobre:)
- Neki pojmovi u Srbiji nisu (bili) lako “pretražljivi”
- Džarao sam neke stvari oko ovoga i bla, bla, bla… uspeo da rešim problem, Srbin ih je na kraju sve zajebao, što kaže u onom vicu