
I will try to explain my process how to get best out of Insta360 ONE RS 1-inch camera and successfully upload images to Mapillary. It started out of my frustration of dealing with this camera and Mapillary and I hope you will not have to go through what I have been🙂. I will be focusing here more on software side (how to deal with data) rather than on hardware side (how to set up rig for image capture)….
O zelenim i crvenim lokalnim politikama

Imao sam ovih dana interesantnu raspravu sa drugom oko toga da li treba sagraditi parking u blokovima. Ono što sledi je dekonstrukcija naše rasprave sa malim uplivima filozofije…
Samozagrevajuće jelo

Dobio sam “tip” da probam neko čudno kinesko samozagrevajuće jelo. Napravio sam ceo video o tome i praktično prelazim u vlogger-e…
TeX i interesantan slovni sistem jednačina

Dugo nisam uzeo TeX, da nešto napišem u njemu, pa sam tražio neki izgovor da ga uzmem. A onda naletim na zanimljiv matematičko-lingvistički problem. I eto razloga:)…
Karta biciklističkih staza Beograda
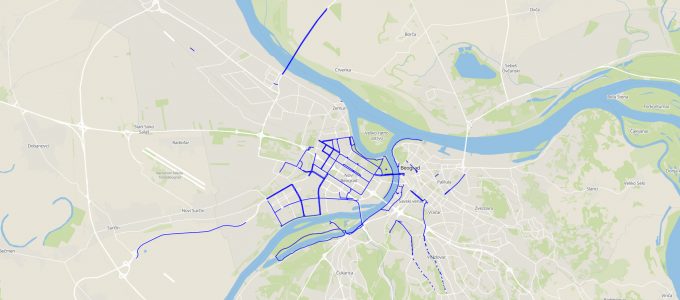
Napravio sam sajt za prikaz svih biciklističkih staza i traka u gradovima Srbije: https://projekti.openstreetmap.rs/bikepaths. Sajt prikazuje statistiku dužine staza (u km) i mogu da se highlight-uju staze po tipu podloge i po osvetljenosti….
Koju opštinu sledeće mapirati?
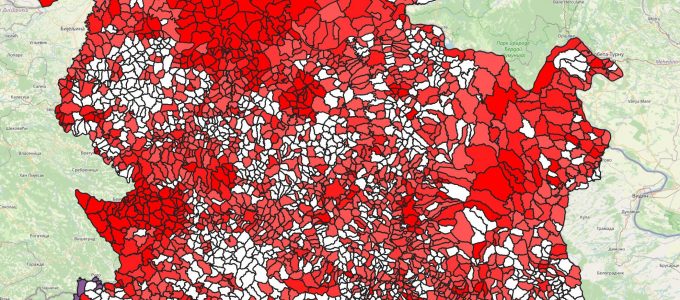
Пре извесног времена смо измапирали све куће у Младеновцу. Поставило се питање коју бисмо следећу општину могли да мапирамо. Било је логично узети неку где је мапираност зграда најгора, али како то наћи?…
Analiza kuća u Mladenovcu
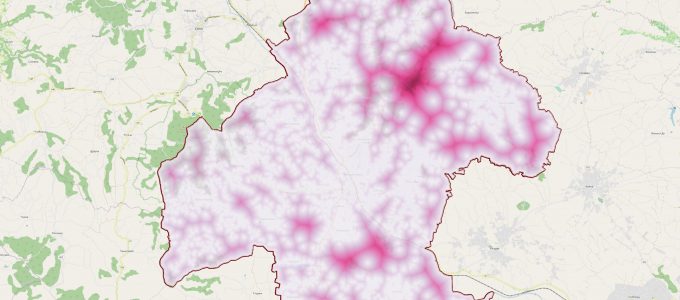
Završili smo akciju mapiranja zgrada u Mladenovcu. Ovde sam uradio analizu šta sve može da se izvuče zanimljivo od tih podataka…
My take why Web3 is being pushed… today
Web3 was never about decentralization and stopping big tech and VCs from controlling you, it is about stopping governments controlling them….
Progress of socio-economic models of web
We had Web1.0. Then Web2.0. This is my take why promise of Web3.0 is fake and why I think it will lead to far worse things than any experience on internet we are having today….